
The state of ITSM in 2020 is characterized by great workplace upheaval. Millions have been made to work from home and others forced to reconfigure workspaces. This has brought significant strain to IT and particularly the Service Desk, which must reorient to a different model of support—particularly with regard to remote access management and connectivity issues on home internet and devices.
PagerDuty recently reported that data from over 12,000 of their enterprise customers shows a doubling of IT incidents in March 2020. Enterprises still maintain the expectation that IT should deliver on its promises for quality in spite of circumstances. One of the main measures for this is responsiveness—and that starts with identifying an issue.
Service desk responsiveness
The ITIL® 4 Practice Guide defines the Service Desk as the resources used to establish an effective entry point and single point of contact with all users in order to capture demand for incident resolution and service requests. These resources include people, tools, and processes such as:
- People, including a team or third party
- Tools, including ITSM solutions, AI, social media channel, and web portals
- Processes, such as incident management, request fulfillment, and change management
The VeriSM service management model has ‘Respond’ as one of its components. This involves supporting the consumer during performance issues, unexpected occurrences, questions, or any other requests. Reacting to incidents and requests—the respond components—has to be underpinned by two main activities:
- Recording some minimum required information from the interaction.
- Managing the interaction to meet the needs of the consumer.
Measuring the responsiveness of the Service Desk happens during the managing activity, as the Service Desk processes must be organized to ensure consistency in the experience for the customer throughout the response and resolution of the incident. Customer satisfaction will most definitely be anchored on the handling of the interaction in line with expectations as defined in the SLA.
Mean time to identify (MTTI)
To consistently address issues raised at the Service Desk, you must focus on monitoring, reporting, and reviewing speed of responsiveness. Mean Time to Identify (MTTI) is a key indicator that can provide visibility on Service Desk performance and point to improvement opportunities. (MTTI is sometimes referenced as Mean Time to Detect or MTTD.)
MTTI is defined as the average time it takes to recognize issues in service or component performance. MTTI is driven by capabilities in proactive monitoring that enable quick validation and triaging of customer issues in order to determine the most appropriate response.
For example, issues can be identified by reviewing application or component status on a monitoring system dashboard or cloud service status page, or even checking transaction trends which show deviation from normal, such as a huge drop in attempts or successes or a spike in errors.
In his blog, Brent Chapman identified key timestamps (Figure 1, images from IBM) that, when analyzed, identify opportunities for improvement in incident response. MTTI would be an average of the difference between start and detection (identification) time for multiple incidents.
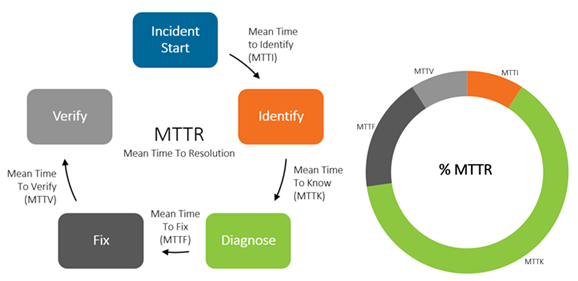
Figure 1: Timestamps that help identify improvement opportunities in incident response
Time to Detect is fairly easy to measure from the basis of monitoring systems, but care has to be taken especially when dealing with false positives and alert fatigue. Chapman gives some good advice on the best way to shorten MTTI: by monitoring customer and service experience rather than component performance.
How to reduce MTTI
The benefits of improved MTTI at the Service Desk include:
- Reducing service unavailability and performance degradation
- Reducing costs associated with incidents
- Improving customer perception of handling of incidents and requests—and your reputation
Reducing MTTI is heavily dependent on technology beyond other capabilities. Modern service and customer experience monitoring solutions are heavily dependent on AI and ML, which go beyond basic event and alert management, to introduce features such as predictive and transaction analytics, and detection of patterns, anomalies, and outliers through in depth review of systems logs and user behavior that goes beyond the realm of normal human bandwidth.
However, without the necessary human competencies and established processes, technology alone will fail to address MTTI. Service Desk agents that support these services and components must be equipped with requisite knowledge on underlying configurations as well as distinguishing informal/warning/exception events and alerts, which then allows them to accurately correlate information from these systems and clearly identify where issues are arising.
In addition, there must be well established processes to ensure the Service Desk agents have the right tools and are organized in the right way to identify these issues. There must be a right balance between informativity, granularity, and frequency of monitoring so that less amount of human resource is spent on trying to identify issues that could be better handled by automated solutions.
Low MTTI supports resolution time
As the above images indicate, MTTI is an input into Mean Time to Resolution (MTTR) which is a critical measure in incident management and request fulfillment. As you lower your mean resolution time, you’ll realize many critical benefits, including:
- Shrinking the impact of incidents shrink
- Increasing resiliency
- Reducing dependencies
All this supports a more nimble, rapid release environment—which your internal and external customers will all love.
Additional resources
For more on the service desk and related metrics, browse the BMC Service Management Blog or check out these articles:






