
Performance measurement changes when your business undergoes digital transformation. Traditional service desk metrics work beautifully in pre-digital transformation environments that haven’t yet embraced cloud computing, rapid change, and the acquisition of new digital users, such as Internet of Things (IOT) devices and machine clients.
However, the rapid and continual changes that come with digital transformation require different metrics for effective measurement. And one of the more important metrics to track in a digitally transferred environment is Mean Time to Recovery (MTTR).
What MTTR means in a digitized environment
In a previous post, I discussed a different metric that also uses the MTTR acronym, Mean Time to Repair. Mean Time to Repair is a measure of how long it takes to get a product or subsystem up and running after a failure. It usually but not always, used with items in a traditional data center. Mean Time to Repair is generally defined through the following equation:
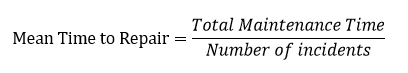
Mean Time to Repair is usually the province of an IT Operations department, as it relates to the physical infrastructure of an organization or devices (such as PCs) that are running inside an organization’s network.
There are some implicit assumptions made when talking about Mean Time to Repair in a traditional environment, including.
- Mean Time to Repair deals with a repairable piece of equipment or a subsystem inside a piece of equipment, such as disk drives, fans, motherboards, and other repairable/replaceable components.
- One technician is performing the repair.
- Any technician performing the repair is trained to make the repair.
The Right MTTR: Moving from Mean Time to Repair to Mean Time to Recovery
These Mean Time to Repair assumptions change when moving to a digitized environment. In a digitized world, it’s more helpful to think in terms of another MTTR definition, Mean Time to Recovery.
Digital transformation encompasses cloud adoption, rapid change, and the implementation of new technologies. It also requires a shift in focus to applications and developers, an increased pace of innovation and deployment, and the acquisition of new digital users–machine agents, Internet of Things (IOT) devices, Application Program Interfaces (APIs), etc.
Fixes are different in digitized environments. What does it mean to “fix” a failed server when you move processing to the cloud, where you may not even know the exact physical location or your servers? A server or telecommunications failure during cloud processing should theoretically be invisible to your users, because (depending on how your contract is structured) processing should simply shift to another cloud-based server or location with no discernable effect on user experience. Unplanned outages should also be handled by the architecture or by automated IT operations technologies, such as AIOps and application-centric infrastructures.
In digitized environments where the user (either human or machine) is accessing your apps in the cloud using their own equipment and apps, Mean Time to Recovery very much relates to the basics of customer experience (CX) and customer acquisition and retention, such as:
- Could the users access your IT services?
- Was service performance degraded, such that users abandoned the app before completion?
- Did the customers experience application errors?
- Did the customers get the results they expected?
In a truly digitized environment, infrastructure and hardware repair is more automated and Mean Time to Recovery refers more to CX rather than hardware issues. The big difference is that CX issues are generally handled by DevOps teams rather than IT Operations.
From Repair to Recovery
Mean Time to Recovery is more important in a digital environment because it refers to the average time that a device (such as a cloud system) will take to recover from any failure. It comes into play when signing contracts that include Service Level Agreement (SLA) targets or for maintenance contracts. In SLA targets and maintenance contracts, you would generally agree to some Mean Time to Recovery metric to provide a minimum service level that you can hold the vendor accountable for.
Theoretically, if your contract specifies that your production server is running under a cloud service and has a Mean Time to Recovery or SLA target of 4 hours, that should be your expectation of how long the server could be down. If your cloud provider has redundant components or clustered servers, your actual Mean Time to Recovery could be zero, as a redundant component or server would kick in automatically after a failure (examples of redundant components and servers might include raided hard drives, backup telecommunication circuits, clustered servers, or multiple DNS or DHCP servers).
The most important things about Mean Time to Recovery metrics or SLA targets is that failure and recovery times for the components must be recorded and reportable. No improvement can happen without measurement.
Make sure you have your MTTRs defined correctly
It’s also important to understand that there are several different varieties of MTTR acronyms that may creep into your contracts, including:
- Mean Time to Repair
- Mean Time to Recovery
- Mean Time to Restore
- Mean Time to Respond
Generally, Mean Time to Repair and Mean Time to Restore have definitions similar to those written above. Mean Time to Restore is sometimes a variation on Mean Time to Recovery. Mean Time to Respond usually refers to the longest amount of time before your maintenance organization will dispatch someone to look at your issue (Mean Time to Respond is popular for standard maintenance contracts on things like printers, where the vendor for example, promises to have someone look at your problem within four hours).
Also remember that the word mean may also refer to the average repair or recovery time. The vendor may be quoting the average response time to fix a particular issue, and the actual issue may be fixed in a longer or shorter time.
The point here is to make sure you have your maintenance metrics clearly and explicitly defined before you sign any contract involving digitized services. Mean Time to Repair/Recovery/Resolve/Respond can mean different things under different circumstances, and it’s important to understand exactly what the vendor is providing.






