
Human-in-the-loop machine learning (HITL ML) allows people to validate a machine learning model’s predictions as right or wrong at the time of training.
HITL allows for training on data that:
- Does not have any labels
- Is hard to tag by automated means
- Constantly evolves
Let’s take a look at this approach to machine learning.
How ML models learn
Learning means having the ability to decrease error. When a child touches a hot stove, the heat, then pain, signals to the child that an error has occurred. We can say the child has learned if he does not touch the hot stove again.
In machine learning, a similar situation takes place. A machine makes a prediction on how a person is feeling based on an image of their face. The computer may predict happy, sad, angry, excited, or neutral. If the machine gets the prediction right, it is rewarded. If the machine gets it wrong, it is penalized.
For a machine to learn, the machine learning loop must have three things:
- The ability to make a prediction.
- A way to measure if the prediction is right or wrong.
- The ability to improve its predictions.
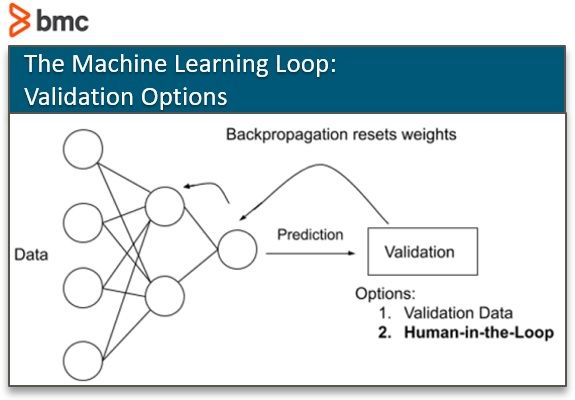
When the model makes its prediction, it can validate the accuracy of its prediction in one of two ways:
- Validation data: Confirm with an already tagged dataset.
- Human in the loop: Allow people to validate or negate the prediction.
It’s this 2nd way that becomes human in the loop machine learning.
The CAPTCHA images on website login forms are used to validate whether the user is a person and not a computer. These CAPTCHAs create their service in order for people to tag image datasets. If their stream of tagged images is directly connected to a machine learning model, it would be using HITL ML.
Reasons for human in the loop ML
A machine learning model might require human in the loop training for several reasons.
- There is not a labeled set of data. If no data set exists, then one must be created. A Human in the Loop method can be used to create one.
- The data set evolves rapidly. If the environment the data is supposed to depict changes rapidly, the model, too, must change rapidly. Human in the loop learning can help keep models up to date with validation datasets from current trends.
- The data is hard to label through automated means. When unlabeled data is hard to label, sometimes the only way to get that data labelled is through a set of human eyes.
Kinds of HITL ML
Humans can be inserted in the training process in several ways.
Humans build only the model
Sometimes ML models need to be trained ahead of time, before deployment. If the design is to build the model, then you can make simulators that allow a model to make a prediction and display that prediction to a human.
Humans train the model
Training a HITL model assumes the model’s predictions start poorly but allows for humans to grade it. Through human judgement, the aim is for the model to start performing at, or better than, human level performance.
Simulators or labelling software can come in different forms. They can be very simple or complex depending on the tasks. Basic labelling tasks can take place in software like spaCy’s Prodigy or Label Studio.
Humans label the data
Data labeling is one way humans can be inserted into the development of a machine learning model.
Every ML model needs labeled data. (Some datasets already have labels.) HITL Machine Learning requires people to label data, and there is plenty of data that needs to be labelled.
Speedy ML enhances experimentation
In both of these HITL systems, data—words, dialogs, images, audio—are presented to a person, the person tags it, then that tagged datapoint validates the model’s prediction, and on the user’s submission, the model’s weights are updated.
Over time, as more and more data is added, the model’s performance should get better. If an ML engineer’s problem is well-defined—it has a narrow scope—then, many NLP and image tasks do not require a long period of HITL training. The lead team at spaCy has said that humans may only need to sit in front of a computer for an hour, labelling 20-100 pieces of data, before the model shows good results.
This quick turnaround is great for building models because it increases the ability to experiment. Whenever the time from hypothesis to result is decreased, people can become better experimenters; their ideas can grow and become refined.
Labelling 20-100 pieces of data doesn’t sound too bad, but the true cost comes in defining the problem the ML model is supposed to solve. That is where the true art lies. If the problem is not defined well, labelers can spend time tagging 20-100 pieces of data, many times over.
More advanced labeling systems could require humans to do the work and allow sensors to “watch”. Simulators are set up for people to remotely control a robot’s arms using a set of controllers and a small camera on the robot’s location. This method might be used to train a robot to sort clothes from a bin, sort recycling from trash, or pick an item off the shelf.
This kind of HITL training allows people to do the work, using robots. Then, data is collected through video cameras mounted on the robot, and the movements the robots make through human control. After thousands of human hours, the robot is slowly able to function on its own.
Use case: machine learning supports UI/UX design
Models do not only need to be built ahead of time. ML models can be created while a software is being used.
Technically, Google’s search engine has always been a form of HITL machine learning. For its search engine, Google’s criteria for success is to provide users with content they wish to find based on words from their query. Google developed a way for their search engine to:
- Make predictions
- Validate the accuracy of that prediction
- Improve its predictions
Given the nature of the game Google created, the validation step could be recorded based on what article a user selected:
- If the first website on the list of websites Google predicted is chosen by a user, then Google’s model made a correct prediction.
- If a user had to click the “Next page” button or had to modify their search and try again, then its prediction was incorrect.
Google’s search engine was designed using principles of Human in the Loop Learning. And its software, and services, got better and better the more and more people were using it.
Google’s example works elsewhere. When UI/UX teams A/B test a new location of a button, a new font, or a new process for users to get through their forms, they are effectively creating a system primed for HITL learning. They create options, make predictions, listen to user feedback, and modify their predictions.
UI/UX teams can automate their design processes by transforming this into a machine learning algorithm. UI/UX teams can create more articulate UX’s by using HITL ML to serve the user a user experience just for them.
The new job: Data labelers
Automation eliminates jobs. Data labeling is a new job in the AI field—and one every Machine Learning model requires.
Data labelling is a low-tech skill. As old low-tech jobs are replaced by automation, the very AI that is used to automate tasks and upending other low-tech jobs, creates a new industry for low-tech workers.
Some datasets, however, can require domain-specific knowledge, like a doctor tagging a lung X-ray as cancerous or not. Though data labelling is low-tech, and mostly low-skill, there are still different values placed on datasets, such as:
- When data is hard to come by. (There are only a handful of robots on Mars to collect the surface temperature and the soil content.)
- When data might require domain-specific knowledge.
Even with all the hype around data, specifically how much data there is, the data that you need for your model’s purpose may not exist.
The IDC says 90% of data is dark data. That means, if the data is out there, there is a good chance the data will need to be labeled or structured in some fashion if it is to be used for machine learning.
Additional resources
For more on this topic, explore the BMC Machine Learning & Big Data Blog or read these articles:
- Bias and Variance in Machine Learning
- What is Machine Learning Operations? MLOps Explained
- Machine Learning: Hype vs Reality
- Top 5 Machine Learning Algorithms for Beginners
These postings are my own and do not necessarily represent BMC's position, strategies, or opinion.
See an error or have a suggestion? Please let us know by emailing blogs@bmc.com.



