Deliver on Service Reliability with BMC Helix and SRE

Site reliability engineering (SRE) is a set of principles and disciplines that helps to achieve reliability for the services a company provides. This article offers an introduction to SRE principles and explains how BMC Helix can help maximize and optimize service and operations reliability.
Site reliability engineering (SRE) is a set of principles and practices that incorporates aspects of software engineering and applies them to IT infrastructure and operations (I&O) problems. The main objective of SRE is to create ultra-scalable and highly reliable software systems. A site reliability engineer spends approximately:
The SRE discipline helps break down silos between software engineering and operations activities within the organization.
(Read our full SRE explainer & comparison to DevOps.)
There have been multiple attempts at defining a canonical list of SRE principles, but these have often lacked consensus. The following characteristics, however, are usually included in most definitions:
SRE is generally characterized by seven principles, including:
These principles focus on key metrics of mean time to failure (MTTF) and mean time to repair (MTTR). Organizations need to implement solutions that not only detect problems proactively but also can scale across the entire enterprise and intelligently automate for consistent service performance and reliability. So how does BMC Helix help organizations achieve SRE excellence?
Enterprise organizations are running and reinventing themselves as they become an Autonomous Digital Enterprise (ADE). They are striving to achieve these three key traits of success:
Organizations turn to BMC Helix to help them reach these success goals for their service and operations needs. BMC Helix solutions are powered by the BMC Helix Platform, which provides an open, scalable, and unified foundation for increased organizational efficiency, productivity, and innovation.
BMC Helix was architected to take full advantage of the requirements needed for SRE as well as seamless integration across the entire enterprise.
 BMC Helix is optimized for SRE-centric capabilities from the platform level to help companies manage services more efficiently and at higher quality
BMC Helix is optimized for SRE-centric capabilities from the platform level to help companies manage services more efficiently and at higher quality
Embracing risk begins with identifying the reliability acceptable by customers. No service or product can ever be 100 percent reliable, and while customers generally accept this fact, they do have a maximum tolerance level. At the same time, improving reliability always incurs cost.
Embracing risk can help weigh the cost versus risk for site reliability engineers and customers. Site reliability engineering aims to strike a balance between the risk of unavailability and the goals of rapid innovation and efficient service operations so that users’ overall happiness—with features, service, and performance—is maximized.
SLOs essentially translate customer satisfaction into internal goals. An SLO is composed of an SLI, a duration, and a target. For example, an SLI might be the ratio of the number of responses with HTTP code 200 to the total number of responses. The duration is the total time in which a metric is measured. This period can be calendar-based (for example, from the first day of one month to the first day of the next) or a rolling window (for example, the previous 30 days).
The target might be the desired percentage of good events to total events (such as 99.9 percent) that you expect to meet for a given duration.
Here are some SLO examples:
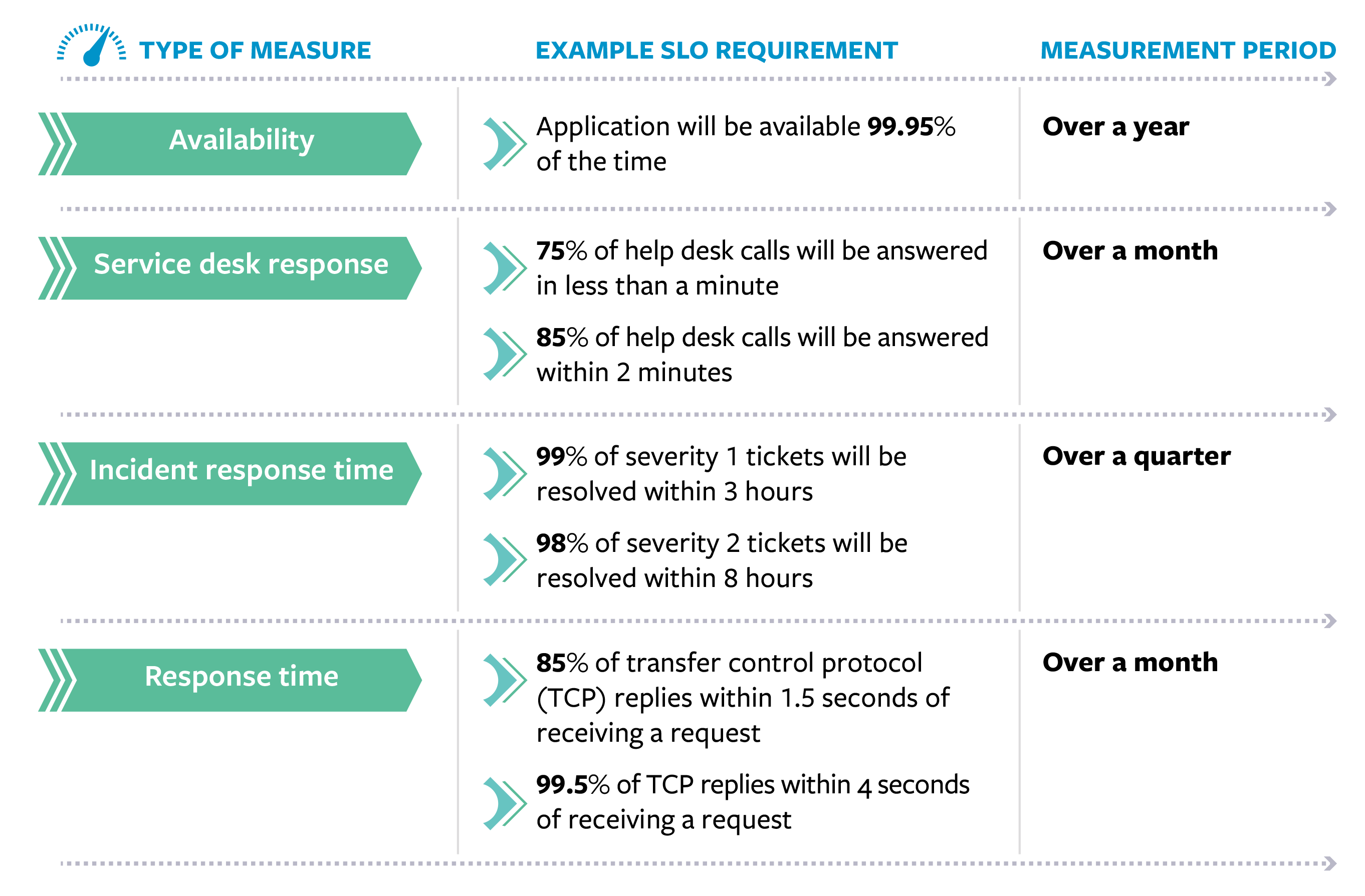 Setting these goals requires intuition, experience, and an understanding of what users expect so that organizations can set achievable SLIs, SLOs, and SLAs.
Setting these goals requires intuition, experience, and an understanding of what users expect so that organizations can set achievable SLIs, SLOs, and SLAs.
These measurements describe the basic metrics that matter and how to measure them, what values we want those metrics to have, and how we’ll react if we can’t provide the expected service. To set the SLOs effectively, you need to be able to understand customer pain points and budget accordingly. You may also have to modify them as customer experience dictates.
Eliminating toil means reducing the number of mundane tasks performed by a site reliability engineer. With increasing automation, many of the activities performed by an SRE this year won’t need to be accomplished manually next year. Key aspects of eliminating toil are to identify the repetitive tasks and automate those activities. The benefit of this is that organizations free up resources and upskill or simply better employ them.
Monitoring is foundational to SRE principles. In an SRE world, organizations need to monitor, manage, and optimize the end-to-end performance and availability of infrastructure and applications across increasingly complex and hybrid IT environments. At the same time, they need to support the agility, speed, and scalability required by SRE initiatives.
In “Monitoring Distributed Systems,” the author states that metrics and structured logging are the two data sources best suited for SRE monitoring needs as they can provide insights for trend analysis and troubleshooting, which point to the root cause.
“The Four Golden Signals” are the most common metrics used to measure site reliability:
The BMC Helix Platform meets all the requirements for a modern monitoring strategy and provides a cohesive platform to deliver all the phases of AIOps like observe (monitoring), engage (ITSM), and act (automation).
Automation frees teams from repetitive tasks, such as scaling resources as the workload demands and optimizing resources by analyzing workload needs.
Release engineering looks at building and deploying software in a consistent, stable, and repeatable way. Running reliable services requires reliable release processes. Site reliability engineers need to know that the binaries and configurations they use are built in a reproducible, automated way so that releases are repeatable and aren’t “unique snowflakes.” Changes to any aspect of the release process should be intentional rather than accidental.
Simplicity is an important goal for site reliability engineers, as it strongly correlates with reliability. Simple software breaks less often and is easier and faster to fix when it does break.
Simplicity for a site reliability engineer is a holistic and end-to-end approach to reliability. It should extend beyond the code itself to the system architecture, tools, and processes used to manage the software lifecycle. The SRE team is in an excellent position to identify, prevent, and fix sources of complexity, whether they are found in software design, system architecture, configuration, deployment processes, or elsewhere, because of their end-to-end understanding of the systems.
To summarize, BMC Helix is the only unified solution with modern, containerized architecture and a deployment model “of choice” available in the market today. These capabilities enable organizations to adopt and implement SRE principles seamlessly.
BMC Helix provides key functionality and differentiation with its ServiceOps approach, which enables collaboration, communication, and orchestration across the enterprise for faster, higher quality service. BMC continues to deliver innovation on SRE-centric capabilities to help organizations align with SRE principles for managing their services more efficiently.
Adkins, Heather, Beyer, Betsy, Blankinship, Paul, Lewandowski, Piotr, Oprea, Ana, Stubblefield, Adam. Building Secure & Reliable Systems. O’Reilly Media, Inc., Sebastopol, CA, March 2020.
Beyer, Betsy, Jones, Chris, Murphy, Niall, Petoff, Jennifer. Site Reliability Engineering, https://sre.google/sre-book/table-of-contents/, O’Reilly, Accessed November 2021.
Beyer, Betsy, Kawahara, Kent, Murphy, Niall Richard, Rensin, David, Thorne, Stephen. The Site Reliability Workbook, https://sre.google/workbook/table-of-contents/, O’Reilly, Accessed November 2021.
Ewaschuk, Rob, SRE.Google Workbook: Chapter 6 – Monitoring Distributed Systems, https://sre.google/sre-book/monitoring-distributed-systems/, O’Reilly, Accessed November 2021.
Frame, Jess, SRE.Google Workbook: Chapter 4 – Monitoring, https://sre.google/workbook/monitoring/, Accessed November 2021.
Sloss, Benjamin Treynor, https://www.oreilly.com/content/tenets-of-sre/, October 6, 2017, Accessed November 2021.